
Intelligente IT-Systeme strukturieren und verdichten Informationen. Das entlastet Mitarbeiter und beschleunigt Abläufe. Der Mensch bleibt dennoch als fachliche und organisatorische Instanz unverzichtbar. Die Basis aller Erfolge sind zudem gut gepflegte Daten.
AI-Ready Data: Ein Prompt ins System, eine flüssige Antwort zurück, und das in Sekundenschnelle: Große Sprachmodelle wie ChatGPT haben die Hürden für die Nutzung Künstlicher Intelligenz (KI) in Unternehmen vermeintlich eingerissen. Genau diese Niederschwelligkeit verstellt allerdings häufig den Blick auf den eigentlichen Engpass.
In der Praxis scheitern KI-Projekte selten an der Wahl oder Größe des Sprachmodells. Die größte Hürde besteht vielmehr darin, dass Unternehmen den versteckten Aufwand unterschätzen, die eigene Wissensbasis in eine Form zu bringen, mit der AI-Ready Data überhaupt erst möglich wird. Der wahre Kraftakt steckt im Verstehen, Strukturieren und Kontextualisieren des Wissens einer Organisation.
Der eigentliche Wert entsteht vor der Antwort
„Trust In AI“, also Vertrauen in KI im Unternehmenskontext lässt sich auf vier konkrete Fragen herunterbrechen: Kann ich den Daten trauen, auf deren Basis die KI arbeitet? Sind sie aktuell, vollständig und fachlich konsistent? Ist nachvollziehbar, warum ein Ergebnis entsteht? Wurden die relevanten Informationen überhaupt von der KI hinzugezogen – oder nur das, was zufällig leicht verfügbar war?
Genau hier stoßen die Sprachmodelle an ihre Grenzen. Sie können keine Ordnung in Datenbestände bringen, die widersprüchlich, lückenhaft oder semantisch unscharf sind. Die beeindruckende Fähigkeit dieser Anwendungen, plausibel zu formulieren, wird hier zum Risiko: Schnell kommt es vor, dass die Antworten über mangelhaften Input hinweg geglättet werden.
Datenpflege erfordert viel Arbeit
Vielerorts wird der Nutzen Künstlicher Intelligenz noch immer an der Qualität ihrer Ausgabe gemessen. Dabei entsteht für Unternehmen der Mehrwert – und auch der Aufwand – dort, wo es darum geht, Daten zu qualifizieren, Kontext aufzubauen und Wissensstrukturen zu pflegen. Diese Vorarbeit entscheidet darüber, ob sich die Ergebnisse intelligenter Anwendungen messen, erklären und reproduzieren lassen.
🎓 Webinar-Tipp: Datenmigration als Grundlage für erfolgreiche KI-Projekte Die Qualität von KI-Ergebnissen hängt entscheidend von konsistenten und sauber strukturierten Daten ab. Fehlerhafte oder unvollständige Datenbestände erschweren Analysen, Automatisierung und den Aufbau belastbarer Wissensstrukturen. Das Webinar der Trovarit Academy zeigt, wie Unternehmen Datenmigrationen strukturiert planen und typische Risiken bei der Übernahme und Bereinigung von Daten vermeiden.
🎓 Webinar: Erfolgreiche Datenmigration – Tipps und Tricks für ein reibungsloses Verfahren | Referent: Alex Ron
Diese Vorarbeit ist besonders dann wichtig, wenn KI-Systeme skalieren sollen. Dann geht es um Konsistenz, Nachvollziehbarkeit, quantitative Auswertung und die Fähigkeit, mit großen Dokumentenmengen kontrolliert umzugehen. Genau in dieser Schnittmenge aus sprachlichen, fachlichen und quantitativen Aspekten stoßen Sprachmodelle regelmäßig an Grenzen.
AI-Ready Data ist mehr als verfügbare Daten
Umfangreiche Datenbestände allein machen Daten noch nicht zu AI-Ready Data und damit nicht automatisch KI-tauglich. Wer aus unverbundenen Dokumenten, Dubletten, Freitexten und Altdaten direkt belastbare Ergebnisse erwartet, der verwechselt Datenverfügbarkeit mit Datenqualität.
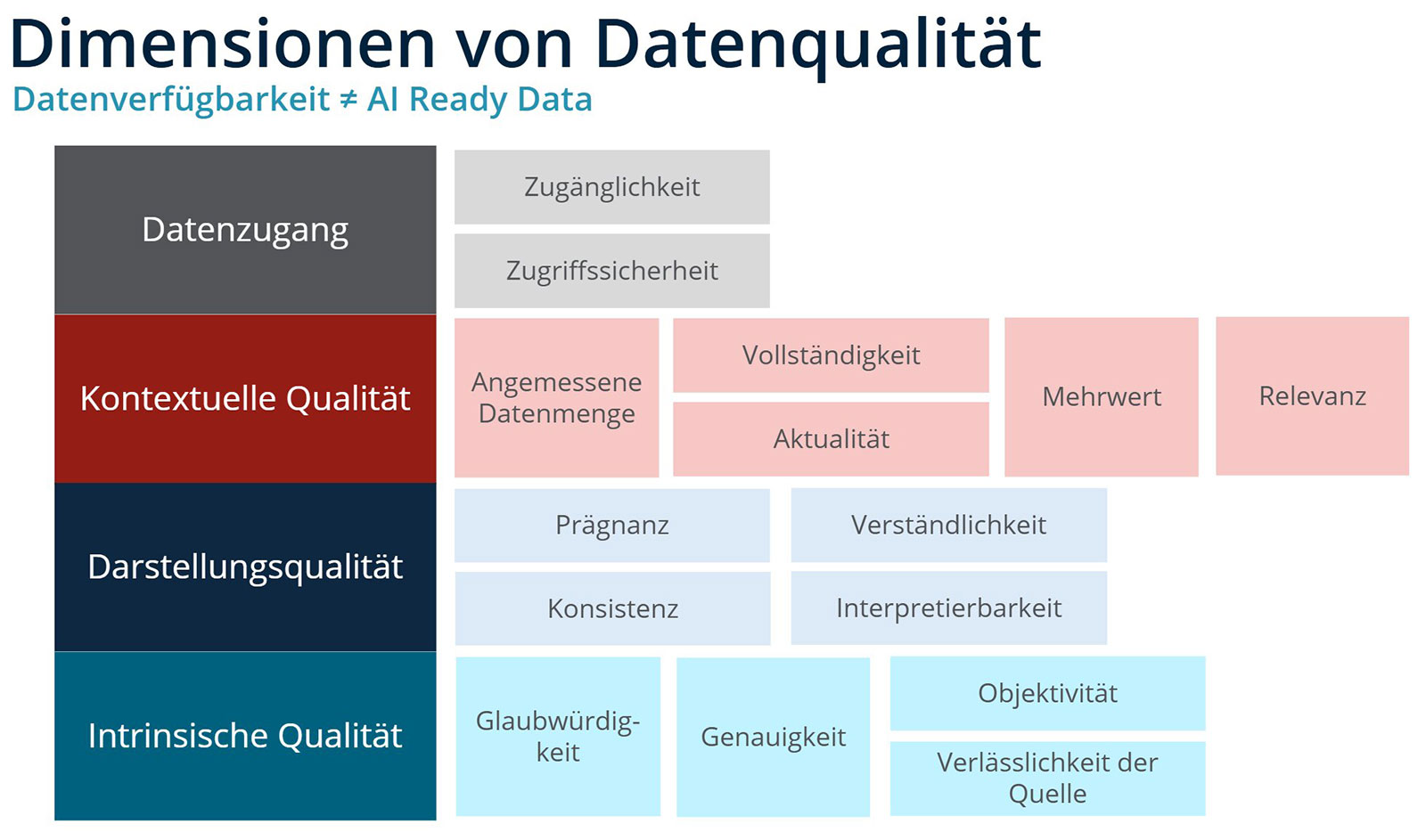
Für wiederkehrende Prozesse, automatisierte Entscheidungen oder regulatorisch sensible Kontexte braucht es einen robusten Rahmen. Dieser entscheidet sich anhand von sechs Leitfragen: Sind Informationen eindeutig? Lassen sich Quellen zurückverfolgen? Gibt es Widersprüche zwischen Systemen? Fehlen entscheidende Felder? Sind Dokumente fachlich sauber verschlagwortet? Ist erkennbar, welche Inhalte veraltet, welche gültig und welche nur lokal relevant sind?
Sprachmodelle lösen keine Bedeutungsprobleme
Dokumentenbestände wachsen in Unternehmen zumeist historisch. Begriffe wandern zwischen Abteilungen, Systemen und Dateiformaten. Dasselbe Wort kann in einem Bauunternehmen etwas anderes meinen als in der Versicherung oder in der technischen Dokumentation. Menschen macht das nichts aus, weil sie ihre Domäne kennen. Für Künstliche Intelligenz allerdings ist es ein Problem der Semantik.
Damit ein System fachlich belastbar arbeitet, reichen Rohdaten nicht aus. Es braucht Metadaten, Glossare, Referenzstrukturen und semantische Einordnungen, die deutlich machen, was ein Begriff im jeweiligen Kontext tatsächlich meint. Erst dadurch entsteht ein Arbeitskontext, in dem „richtig“ mehr bedeutet als sprachlich plausibel oder statistisch wahrscheinlich.
Teile des Fachwissens sind für IT nicht zugänglich
Ein nicht zu unterschätzender Teil des Wissensschatzes von Unternehmen liegt gar nicht in Datenform vor, sondern in Routinen, Ausnahmen, impliziten Regeln und Erfahrungswissen. Die Fachbereiche wissen, welche Quelle verlässlich ist, welcher Wert formal korrekt, aber praktisch irrelevant bleibt, oder welche Formulierung intern eine besondere Bedeutung trägt. Dieses Wissen wurde allerdings vielerorts nie sauber dokumentiert, weil es im Arbeitsalltag unter Menschen stillschweigend zur Anwendung kommt.
Künstliche Intelligenz hingegen lebt von expliziten Signalen. Die Algorithmen müssen lernen, wie eine Organisation ihre Sprache verwendet, welche Kategorien üblich sind und welche Abweichungen geschäftskritisch werden. Genau deshalb greift das Prinzip Human in the Loop zu kurz, wenn Fachabteilungen Ergebnisse erst am Ende prüfen. Die Experten müssen früher hinzugezogen werden: beim Klären von Begriffen, beim Beschreiben von Regeln, beim Bewerten von Quellen und schließlich bei der Frage, welche Kontexte für eine belastbare Antwort zwingend dazugehören.
Der Mensch bleibt im Prozess unverzichtbar
Der schwierige Teil vieler KI-Projekte beginnt damit, dass Experten erklären müssen, wie sie denken. Das ist aufwändig. Es ist aber oft die Voraussetzung dafür, dass aus einem sprachgewandten System ein fachlich nutzbares wird. Unabhängig vom gewählten Sprachmodell gilt: KI kann verdichten, strukturieren, vorbereiten, vergleichen und Abläufe beschleunigen. Algorithmen durchdringen große Mengen an Informationen und nehmen Fachleuten Arbeit ab, die bislang Zeit, Aufmerksamkeit und Nerven kostet. Auch die beste Technologie kann wichtige Aufgaben nicht übernehmen, widersprüchliche Daten stillschweigend heilen oder den vollen Organisationskontext aus dem Stand heraus verstehen. Der Mensch bleibt deshalb im Prozess unverzichtbar – als fachliche und organisatorische Instanz. jf
Der Autor

Prof. Dr. Heiko Beier ist Geschäftsführer von moresophy und Professor für Digitale Medienkommunikation und Künstliche Intelligenz. Er verfügt über mehr als 25 Jahre Erfahrung in der Datenanalyse und im Automatisieren von Geschäftsprozessen.


